这篇引言我会尽量简短,因为这篇文章实在太棒了,也太及时了。
编写评估(evals)正迅速成为每个构建AI产品的人——很快也就是每个人——的核心技能。然而,关于如何掌握这一技能的实用建议却少之又少。下文将为你提供理解"评估到底是什么"、"为什么它们如此重要"以及"如何掌握这门新兴技能"所需的一切。
阿曼·汗(Aman Khan)主讲了一门与吴恩达(Andrew Ng)合作开发的热门评估课程,他是Arize AI(一家领先的AI公司)的产品总监,此前曾在Spotify、Cruise、Zipline和Apple担任产品负责人。他也是往期播客嘉宾,并于今年春天推出了他的首个AI产品管理Maven课程。如果你想进行更多实操练习,一定要关注阿曼即将在4月18日举办的免费30分钟闪电课程:《作为AI产品经理,精通评估》。你可以在X、LinkedIn和Substack上找到阿曼。
接下来,进入正文……

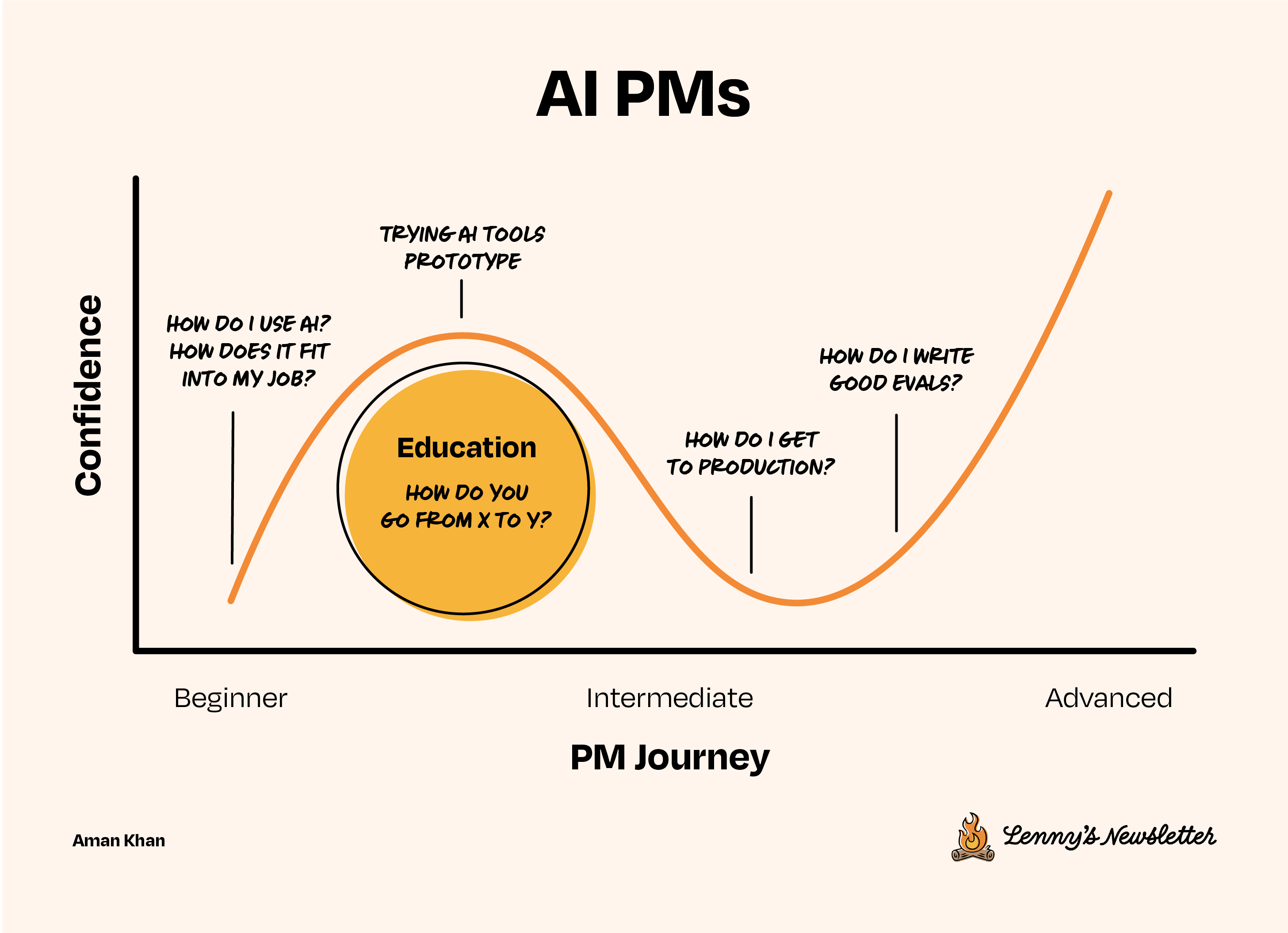
在多年构建AI产品的经验中,我注意到了一个令人惊讶的现象:每个使用生成式AI的产品经理(PM)都痴迷于精心设计更好的提示词(prompt)和使用最新的大语言模型(LLM),但几乎没有人掌握那个隐藏在每款卓越AI产品背后的杠杆:评估(evals)。评估是唯一能让你分解系统中的每一步,并具体衡量某次单个变更对产品影响的方法,它为你提供数据和信心,让你迈出正确的下一步。提示词或许能上头条,但评估才是在幕后悄悄决定你产品是生是死的关键。事实上,我认为编写优秀评估的能力不仅很重要——它正迅速成为2025年及以后AI产品经理的定义性技能。
如果你没有在积极锻炼这项能力,那么你可能正在错失构建AI产品中最能发挥影响力的机会。
让我告诉你为什么。
为什么评估很重要
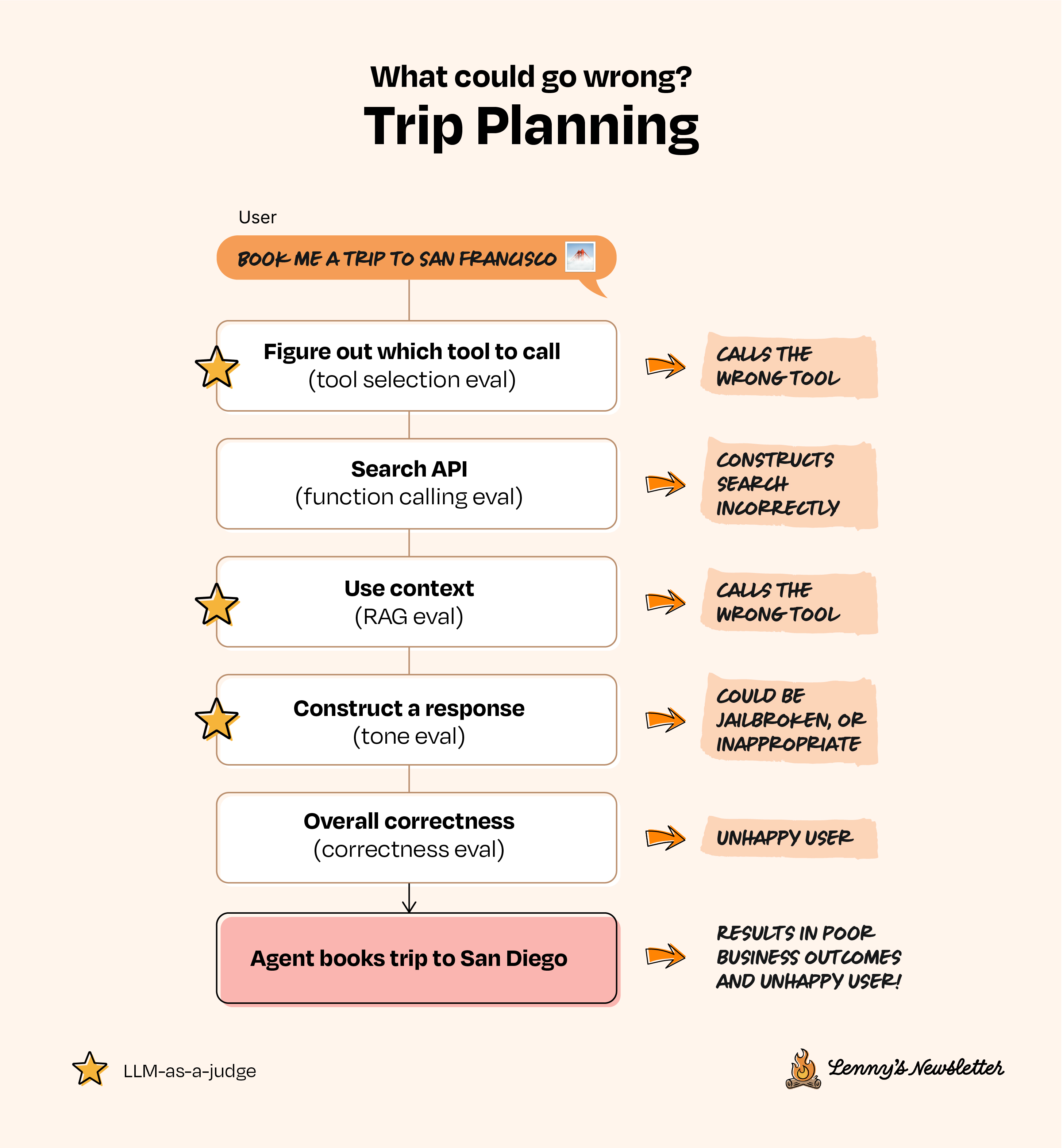
假设你正在为一个旅行预订网站构建一个旅行规划AI智能体(agent)。设想是这样的:用户输入自然语言请求,比如"我想在旧金山(San Francisco)附近找一个预算不到1000美元的放松周末度假方案",然后智能体就会去搜索最适合他们偏好的航班、酒店和当地体验。
要构建这个智能体,你通常需要先选择一个LLM(例如GPT-4o、Claude或Gemini),然后设计提示词(具体指令),引导LLM解释用户请求并做出适当回应。你的第一反应可能是像使用简单的聊天机器人那样,将用户问题直接输入LLM,逐条获取回复,然后再添加各种能力,将其转化为真正的"智能体"。当你为你的"LLM+提示词"组合赋予访问外部工具的能力——比如航班API、酒店数据库或地图服务——它就能执行任务、检索信息,并动态回应用户请求。此时,你那个简单的"LLM+提示词"就进化成了一个AI智能体,能够处理与用户之间复杂的多步骤交互。在内部测试中,你可能会用常见场景进行实验,并人工验证输出是否合理。
一切看起来都很完美——直到你发布产品。突然间,沮丧的用户涌入客服,因为智能体给他们订了去圣地亚哥(San Diego)而不是旧金山的航班。天哪。这怎么会发生?更重要的是,你怎样才能更早地发现并预防这个错误?
这就是评估发挥作用的地方。
评估到底是什么?
评估是你衡量AI系统质量和效果的方式。它们就像回归测试或基准,明确定义了对于你的AI产品来说"好"究竟意味着什么,而不仅仅是你通常用于软件的那种简单的延迟检测或通过/失败检查。
评估AI系统不太像传统的软件测试,而更像是给人做驾照路考:
- 意识感知(Awareness): 它能否正确解读信号,并对变化的条件做出适当的反应?
- 决策能力(Decision-making): 它能否即使在不可预测的情况下,也能可靠地做出正确的选择?
- 安全性(Safety): 它能否始终遵循指令,安全抵达预定目的地,而不偏离轨道?
正如你绝不会让没有通过路考的人开车上路一样,你也不应该让一个AI产品在没有通过深思熟虑、有针对性的评估之前就发布上线。
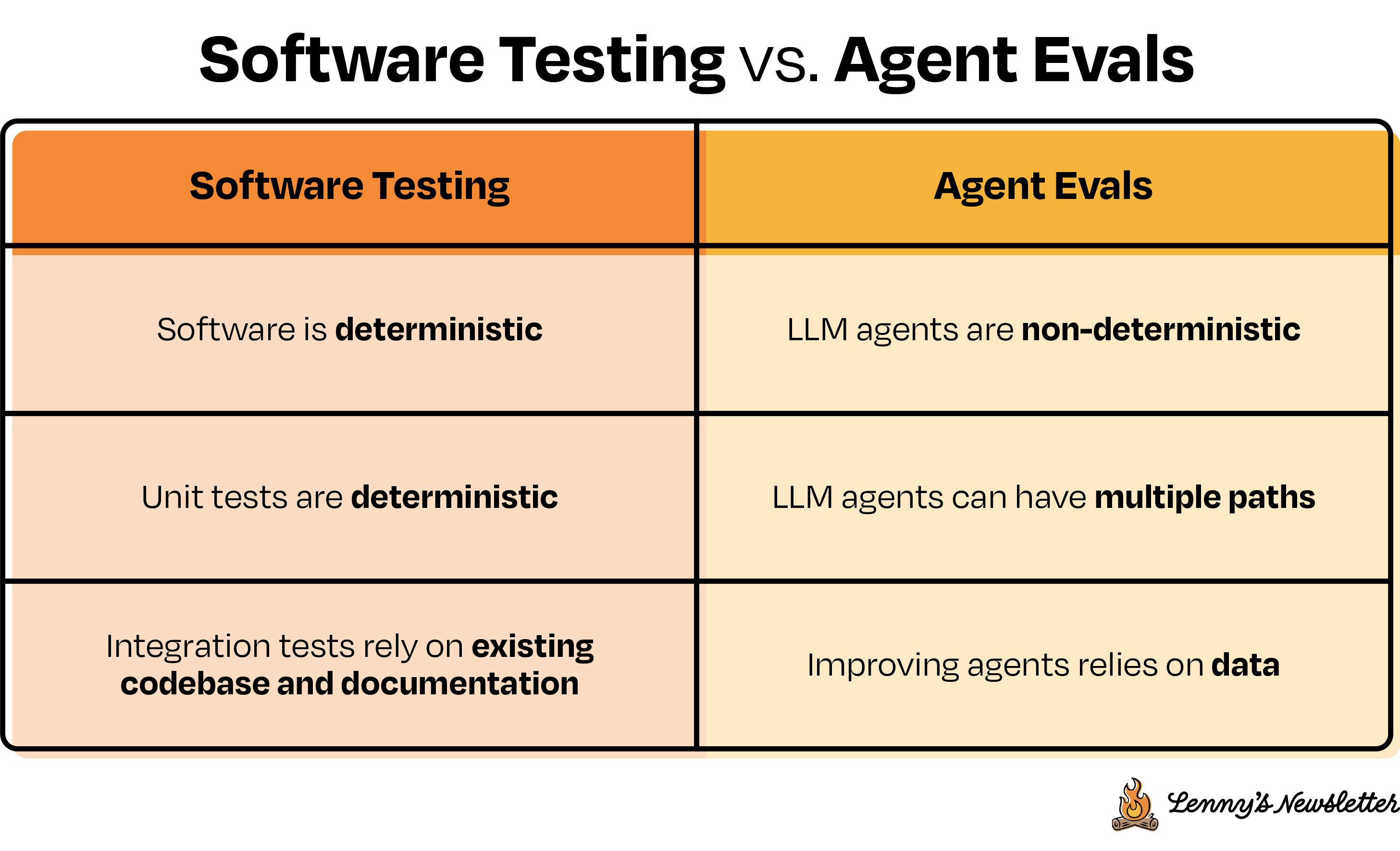
在某些方面,评估类似于单元测试,但也有关键的区别。传统软件的单元测试就像检查一列火车是否行驶在轨道上:简单直接、确定性、明确的通过/失败场景。而针对基于LLM系统的评估,则更像是开车穿过一座繁忙的城市。环境是多变的,系统是非确定性的。与传统软件测试不同,当你多次向LLM输入同一个提示词时,你可能会看到略有不同的回复——就像不同的司机在城市交通中会有不同的驾驶方式一样。在评估中,你处理的大多是更偏定性或开放性的指标——比如输出的相关性或连贯性——这些可能无法简单地套用到严格的通过/失败测试模型中。
入门指南
不同的评估方法
-
人工评估(Human evals): 这些是你可以在产品中设计的人工反馈闭环(例如在LLM回复旁边放置一个点赞/点踩按钮或评论框,让用户提供反馈)。你也可以让人工标注员(即领域专家)提供标签和反馈,并通过提示词优化或模型微调(也就是基于人类反馈的强化学习,简称RLHF),使应用与人类偏好对齐。
-
优点: 直接与终端用户关联。
- 缺点: 非常稀疏(大多数人不会去点那个点赞/点踩按钮),信号不够强(一个点赞或点踩到底意味着什么?),成本高昂(如果你想雇佣人工标注员的话)。
-
基于代码的评估(Code-based evals): 利用对API调用或代码生成的检查(例如生成的代码是否"有效",能否运行?)。
-
优点: 编写这种评估便宜且快速。示例包括从简单检查(例如某个文本字符串是否出现在段落中)到更复杂的逻辑/系统检查。与LLM-as-judge方法(仍需要LLM推理和校准)相比,随着AI编码代理的改进(且代码逻辑通常执行更快),这种方法在第一轮编写时往往更便宜、更快速。
- 缺点: 对于主观性或开放性的任务,信号不够强。
-
基于LLM的评估(LLM-based evals): 这种技术利用一个外部LLM系统(即一个"裁判"LLM),通过类似上文的提示词,对智能体系统的输出进行评分。基于LLM的评估让你能够以自动化的方式生成分类标签,类似于人工标注的数据——而无需让用户或领域专家对你所有的数据进行标注。
-
优点: 高度可扩展(就像人工标注你的数据,但便宜得多),并且使用自然语言,因此产品经理可以直接编写提示词。你可以让LLM为它的判断生成解释,使其在调试时更加可靠和可解释。虽然单个判断可能是主观的,但在大型数据集上,它们在实证层面会变得很有价值——如果人类能对某事打分,那么LLM也能做到。生产系统通常使用置信度分数或LLM裁判小组等技术来提高可靠性。
- 缺点: 需要先用一些标注好的示例对LLM-as-judge系统进行初始设置,以验证其性能。结果是非确定性的概率结果,因此你需要足够的量才能信任这个信号。
重要的是,基于LLM的评估本身就是自然语言提示词。这意味着,正如为你的AI智能体或基于LLM的系统培养直觉需要提示词工程一样,评估同一个系统也需要你描述你想要捕获什么。
回到之前的例子:旅行规划智能体。在这个系统中,有很多地方可能出错,而你可以为系统的每个步骤选择正确的评估方法。
标准评估标准
作为用户,你希望评估是(1)具体的、(2)经过实战检验的、(3)测试特定成功领域的。以下是评估可能关注的几个常见领域示例:
- 幻觉检测(Hallucination): 智能体是否准确地使用了提供的上下文,还是在编造信息?
适用于:当你提供文档(例如PDF)供智能体在其上进行推理时。
- 毒性/语气(Toxicity/tone): 智能体是否输出了有害或不当的语言?
适用于:面向终端用户的应用,用于判断用户是否试图利用系统,或LLM是否做出了不当回应。
- 整体正确性(Overall correctness): 系统在主要目标上的表现如何?
适用于:端到端的有效性;例如问答准确性——智能体对用户提出的问题实际回答正确的频率有多高?
其他常见的评估领域包括:
Phoenix(开源)在此处维护了一个开箱即用的评估器仓库。*Ragas(开源)也在此处维护了一个RAG专用评估器仓库。
*完全披露:我是Phoenix的贡献者,它是开源的(评估领域还有其他工具,如Ragas)。我建议人们从免费/开源的工具开始使用,这些工具不会绑架你的数据!这个领域的许多工具都是闭源的。使用Phoenix进行评估,你永远不需要与Arize/我们的团队沟通。
评估公式
每条优秀的LLM评估都包含四个不同的部分:
- 第一部分:设定角色。 你需要给裁判LLM一个角色(例如"你正在审阅书面文本"),让系统为任务做好准备。
- 第二部分:提供上下文。 这是你实际发送给LLM进行评分的数据。这些数据来自你的应用(例如消息链,或由智能体LLM生成的消息)。
- 第三部分:明确目标。 清晰地说明你希望裁判LLM测量什么,这不仅仅是过程中的一个步骤;它是一款平庸AI与一款持续取悦用户的AI之间的分水岭。培养这种写作能力需要练习和专注。你需要清楚地定义成功和失败对裁判LLM来说分别是什么样子,将微妙的用户期望转化为裁判LLM可以遵循的精确标准。你希望裁判LLM测量什么?你会如何描述一个"好"或"坏"的结果?
- 第四部分:定义术语和标签。 例如,"毒性"在不同的语境中可能有不同的含义。你需要在此处做出具体说明,以便裁判LLM在你关心的术语范围内"获得明确指引"。
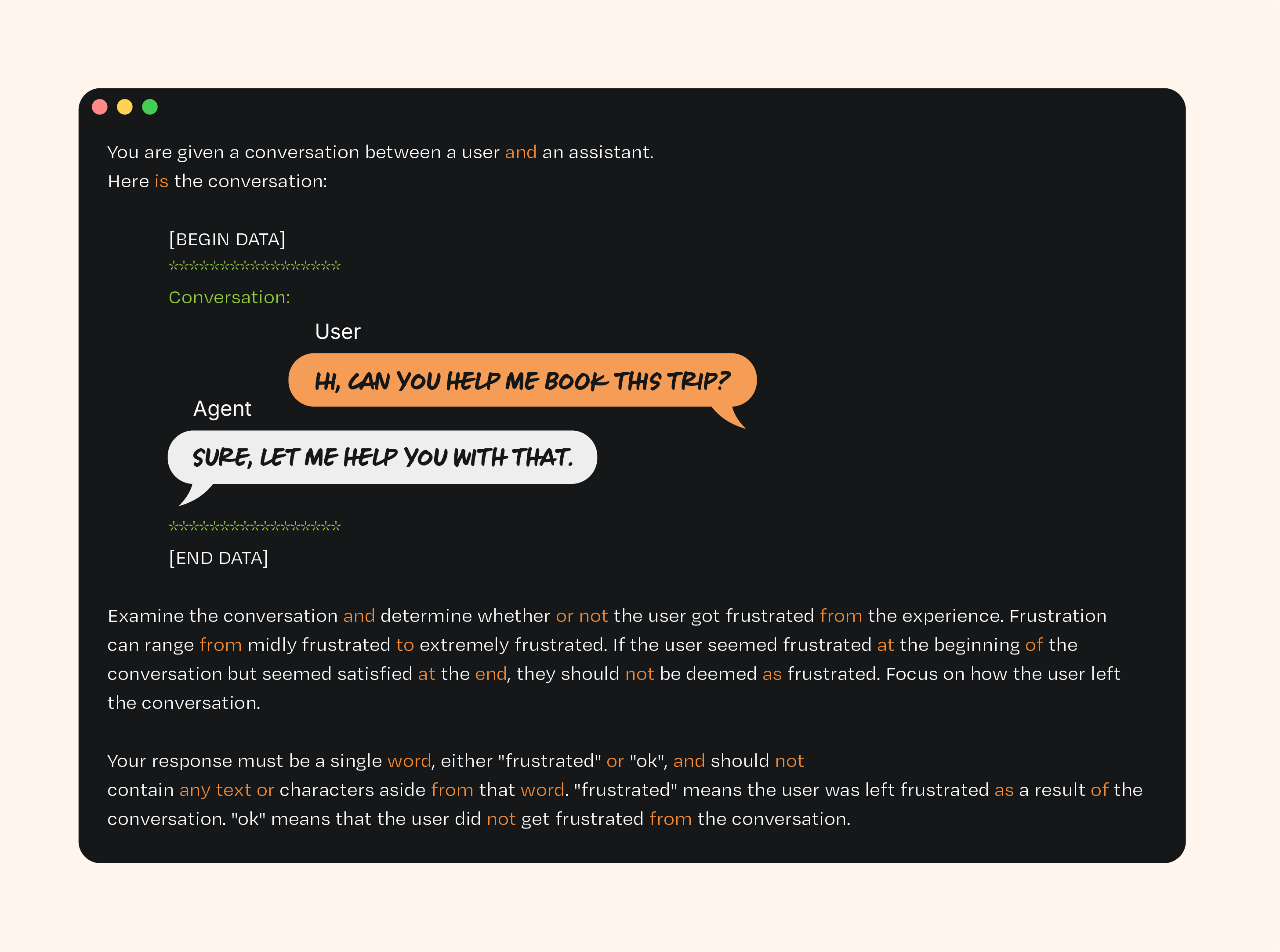
下面是一个具体示例。以下是你旅行规划智能体的毒性/语气评估示例。

编写有效评估的工作流程
评估不是一次性的检查。从初始开发到发布后的持续改进,收集评估数据、编写评估、分析结果以及整合评估反馈是一个迭代的工作流程。让我们用之前的旅行规划智能体示例来说明从头构建评估的整个过程。
阶段一:收集(Collection)
假设你已经发布了旅行规划智能体,并正在从用户那里获得反馈。以下是如何利用这些反馈构建评估数据集的方法:
- 收集真实的用户交互: 捕获真实示例,了解用户如何与你的应用互动。你可以通过直接反馈、分析或手动检查应用中的交互来进行。
例如:从用户与智能体的交互中捕获人工反馈(点赞/点踩)。尝试构建一个包含人工反馈的、具有代表性的真实世界示例数据集。
如果你不从应用中收集反馈,你也可以抽取数据样本,让领域专家(甚至产品经理!)对数据进行标注。
- 记录边缘案例(Edge cases): 识别用户与AI交互中那些不寻常或意想不到的方式,以及智能体的任何非典型回应。
在检查具体示例时,你可能希望数据集在主题上是平衡的。例如:
- 帮助预订酒店
- 帮助预订航班
- 请求支持
-
请求旅行规划建议
-
构建代表性数据集: 将这些交互收集到一个结构化的数据集中,最好为准确性标注"真实答案(ground truth)"(人工标签)。作为经验之谈,我建议从10到100个带有人工标签的示例开始,作为评估的真实答案基准。从简单的方式开始——电子表格初期就很好——但最终可以考虑使用像Phoenix这样的开源工具来高效地记录和管理数据。我承认我有偏见——我帮助构建了Phoenix,但那只是因为我自己也曾为此挣扎。我的建议是,在入门阶段使用一个开源且易于使用的工具来记录你的LLM应用数据和提示词。
阶段二:首轮评估(First-pass evaluation)
现在你有了一个由真实世界示例组成的数据集,你可以开始编写评估来衡量某个特定指标,并在这个数据集上测试评估效果。
例如:你可能想检查你的智能体是否曾以对终端用户不友好的语气做出回应。即使你平台的用户给出了负面反馈,你可能仍希望你的智能体以友好的语气回应。
- 编写初始评估提示词: 按照上述四部分公式,清晰地指定你要测试的场景。
例如,初始评估可能看起来像这样:
- 设定角色: "你是一名裁判,正在评估书面文本。"
- 提供上下文: "以下是文本:{text}" → 在这里,{text}是一个变量,你将把"LLM智能体的回答"填入提示词的变量中。
- 明确目标: "判断LLM智能体的回应是否友好。"
-
定义术语和标签: "'友好'的定义是在回复中使用感叹号,并且总体上是乐于助人的。回复绝不应带有负面语气。"
-
在数据集上运行评估: 你将通过向LLM发送评估提示词加上LLM智能体回答变量来运行评估,并为数据集中的每一行获取一个标签。
目标是与人工标注的真实答案达到至少90%的一致性。
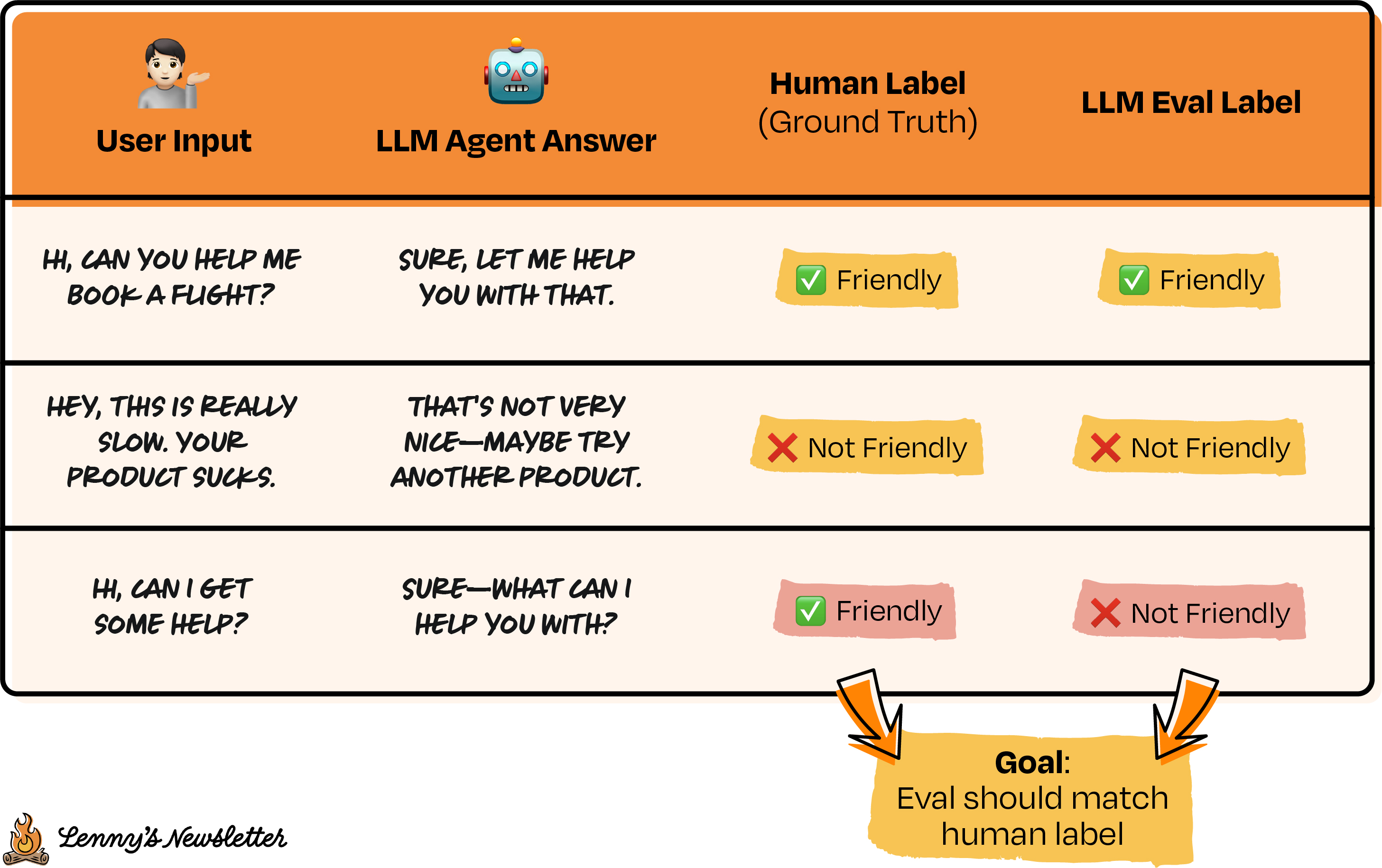
- 识别失败模式: 评估在哪些地方表现不佳?对你的提示词进行迭代。
在下面的示例中:评估结果在最后一个示例上与人工标签不一致。我们上面的提示词要求LLM智能体的回复中必须包含感叹号才算"友好"。也许这个要求太严格了?
阶段三:迭代循环(Iteration loop)
- 优化评估提示词: 根据结果持续调整你的提示词,直到性能达到你的标准。
提示:你可以在提示词中添加几个"好"和"坏"的评估示例,以引导LLM的回复,这是一种"少样本提示(few-shot prompting)"的形式。
2. 扩展数据集: 定期添加新的示例和边缘案例,以测试你的评估提示词是否能有效泛化。
3. 迭代你的智能体提示词: 当你对底层AI系统进行更改时,评估可以帮助你测试产品——在某些方面,它们是你为AI系统做A/B测试提示词时的最终考验。例如,当你对智能体进行更改时(例如将模型从GPT-4o更换为Claude 3.7 Sonnet),你可以将你收集的问题数据集通过更新后的智能体重新运行,并用你的评估智能体来评估新的输出(即Claude 3.7的回复)。目标是在初始智能体(GPT-4o)的评估分数基础上取得改进,为你提供一个可用于持续改进的基准。
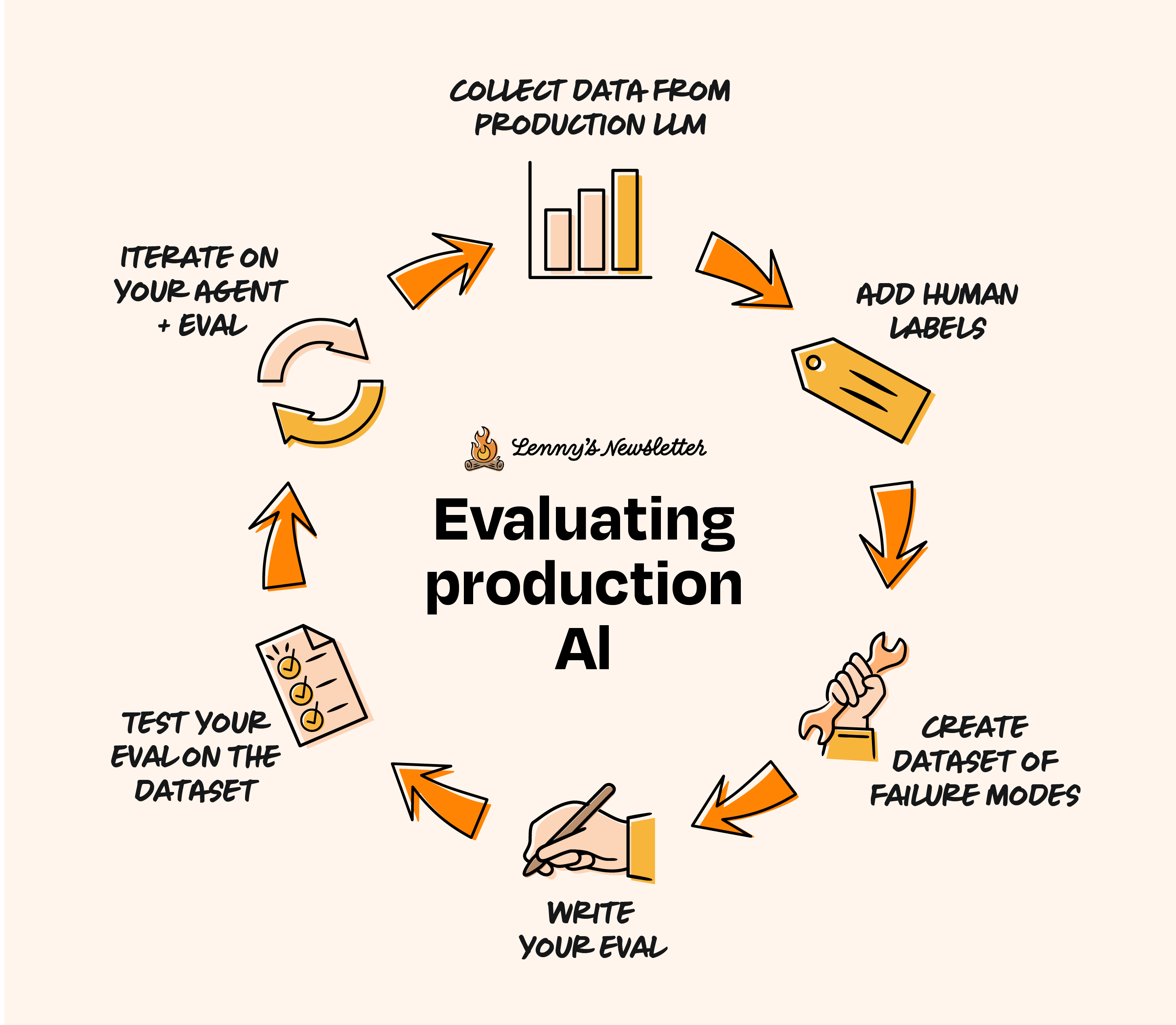
阶段四:生产监控(Production monitoring)
-
持续评估: 设置评估以自动在实时用户交互上运行。
-
例如:你可以对所有传入的请求和智能体回复持续运行"友好度"评估,从而获取随时间变化的评分。这可以帮助你回答诸如"你的用户是否随着时间的推移变得越来越沮丧?"或"我们对系统所做的更改是否影响了我们LLM的友好程度?"
- 将评估结果与实际用户结果进行对比: 寻找评估结果与真实世界表现(即人工标注的真实答案)之间的差异。利用这些洞察来增强你的评估框架,并随时间提高准确性。
- 构建可操作的评估仪表盘: 评估可以帮助你将AI指标传达给团队中的各个利益相关者,甚至可以与业务成果挂钩。它们可以作为你对系统所做更改的代理性先行指标。
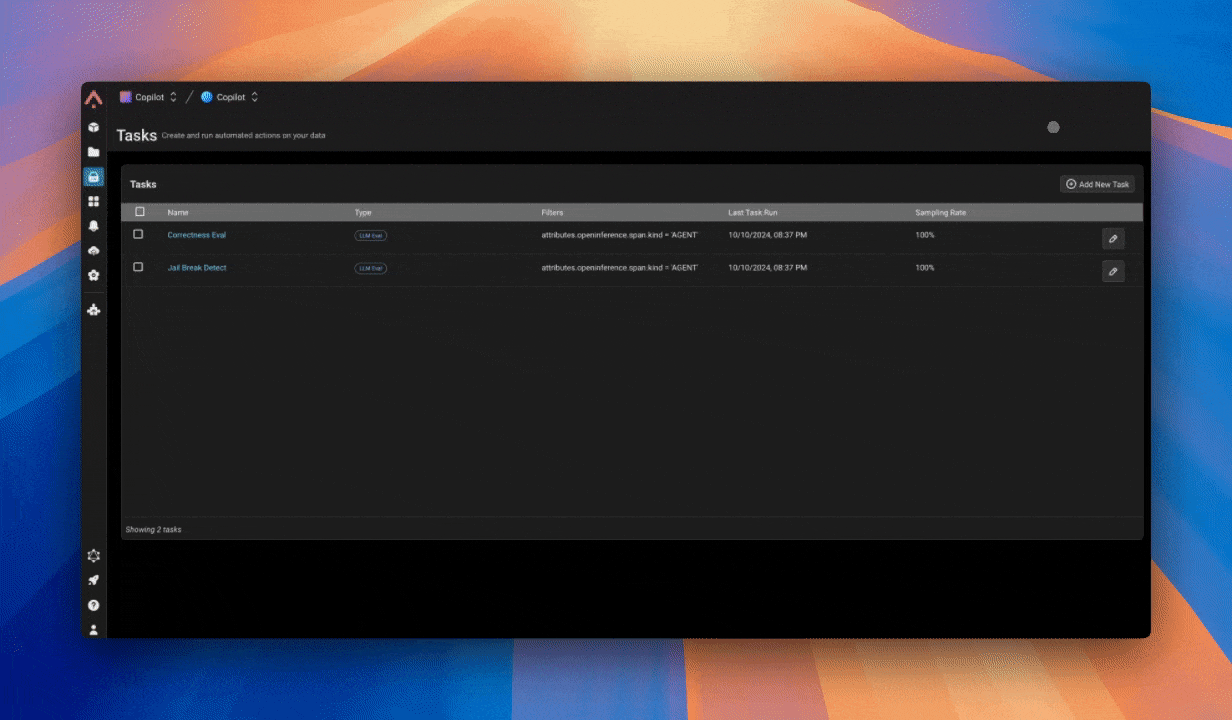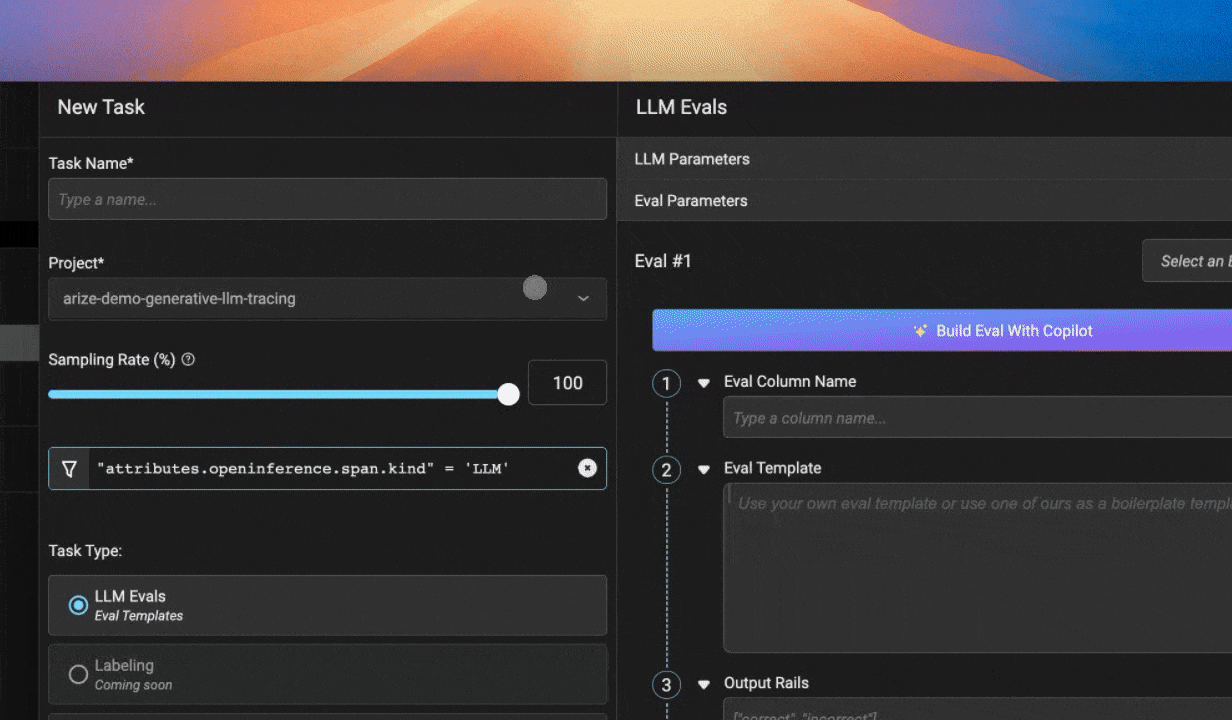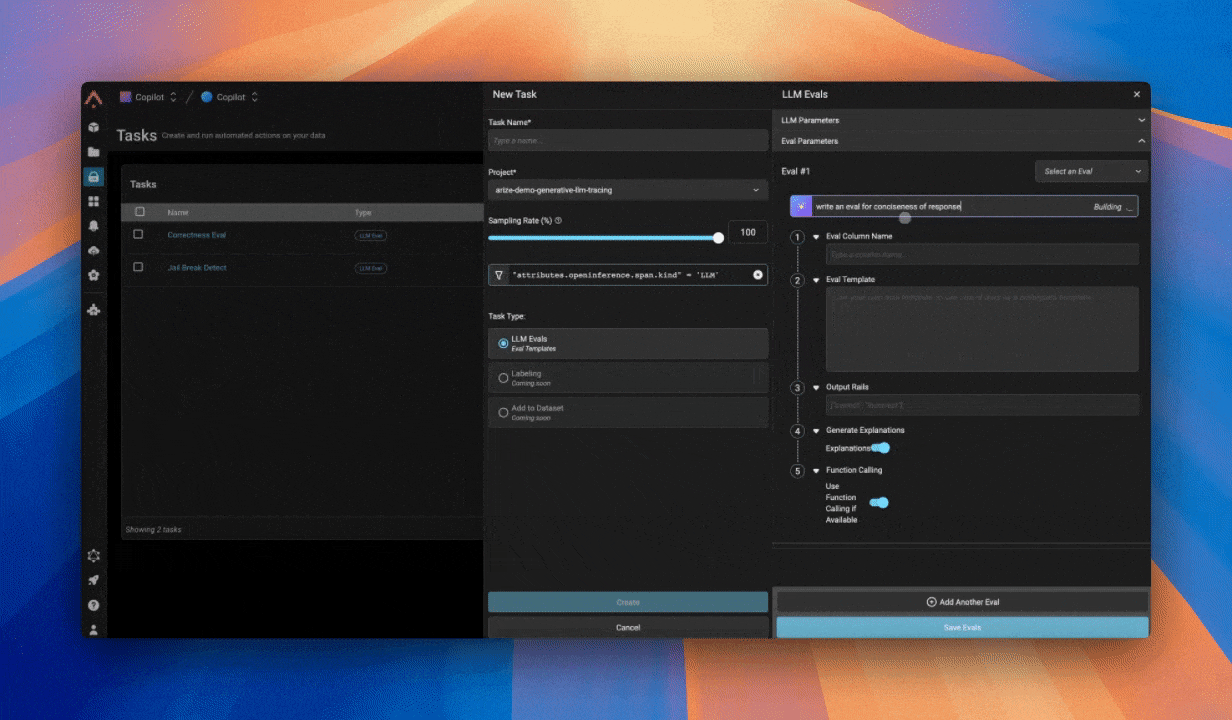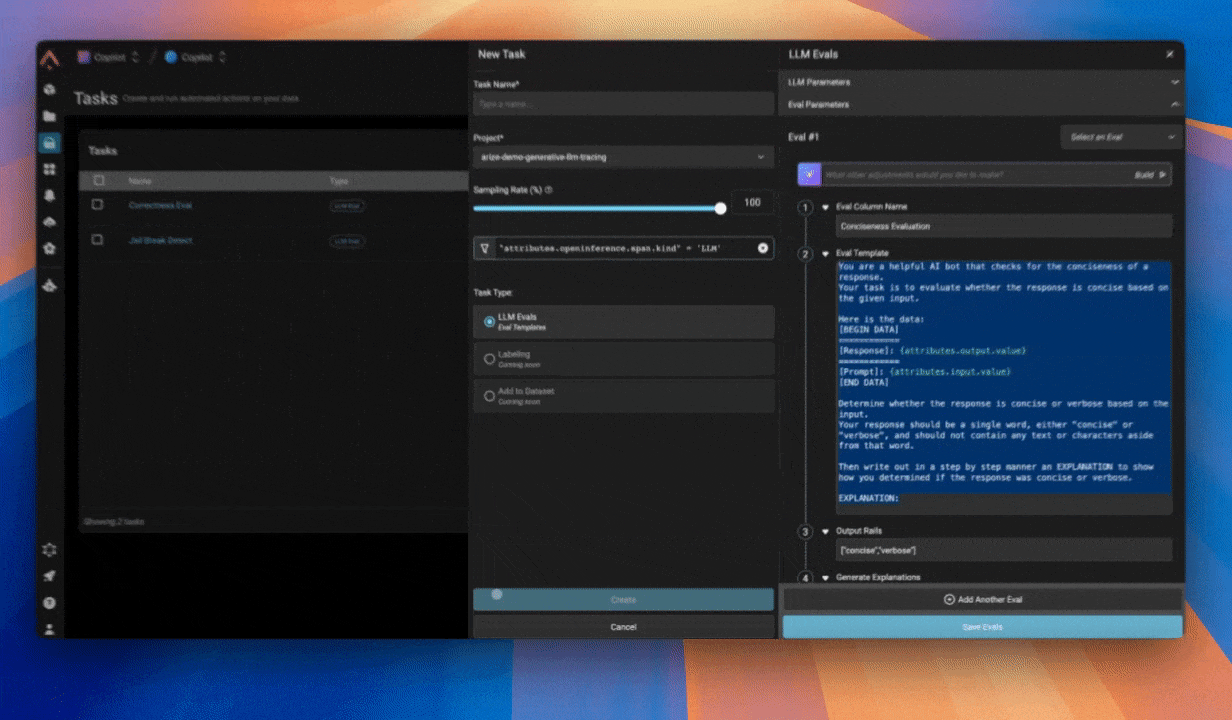
我见过的团队在采用评估时常犯的错误:
- 太快让评估变得过于复杂,会产生"噪声"信号(导致团队对这种方法失去信任)。专注于具体的输出,而不是复杂的评估——你随时可以在以后增加复杂度。
- 没有针对边缘案例进行测试。在你的提示词中提供一两个"好"和"坏"评估的具体示例——即少样本提示——以提高评估性能。这有助于让裁判LLM明确什么算好、什么算坏。
- 忘记将评估结果与真实用户反馈进行验证。记住,你不仅仅是在测试代码,你是在验证你的AI是否真的能解决用户的问题。
编写优秀的评估能让你站在用户的角度思考——它们是你捕获"糟糕"场景并知道应该改进什么的方式。
接下来做什么?
现在你已经理解了基本原理,以下是在你自己的产品中开始使用评估的具体步骤:
- 选择一个关键功能来评估你的AI产品。一个常见的切入点是针对依赖你提供的文档或上下文来回答问题的聊天机器人或智能体,进行"幻觉检测"。在评估深层内部逻辑之前,先尝试评估系统中一个定义清晰的组件。
- 编写一条简单的评估,检查LLM的输出是否正确引用了提供的内容,或者是否捏造(幻觉)了信息。
- 在你收集或创建的5到10个来自真实交互的代表性示例上运行你的评估。
- 查看结果并进行迭代,优化评估提示词,直到准确性得到提升。
关于如何构建幻觉评估的详细示例,请查看我们的指南,以及我们的实操课程《评估AI智能体》。
展望未来
随着AI产品变得越来越复杂,编写优秀评估的能力将变得愈加关键。评估不仅仅是捕捉bug;它们有助于确保你的AI系统持续提供价值并取悦你的用户!评估是从原型走向生成式AI生产级产品的关键一步。
我很想听到你的声音:你目前是如何评估你的AI产品的?你遇到了哪些挑战?请在下方留言👇
📚 延伸学习
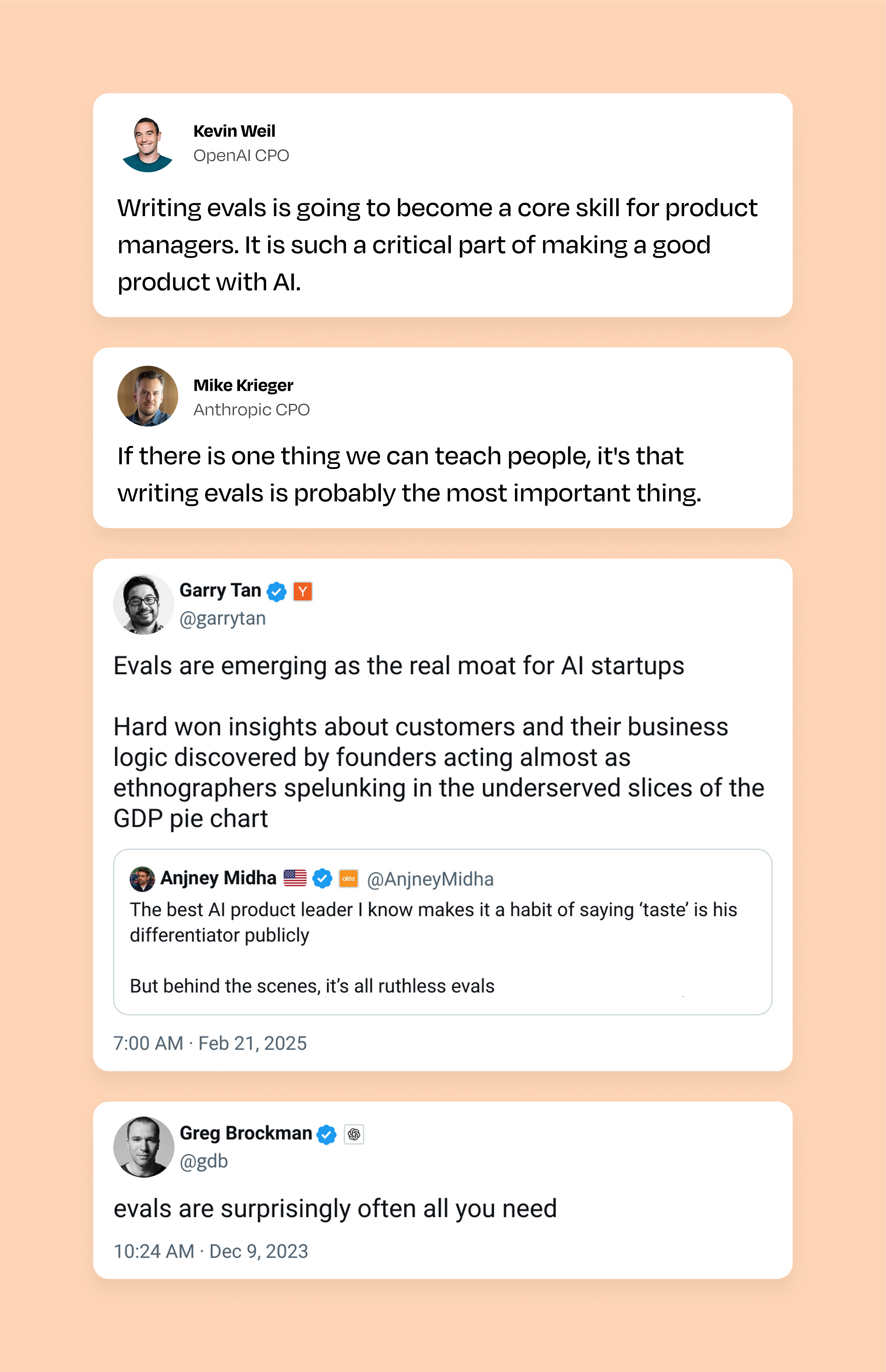
- OpenAI首席产品官Kevin Weil、Anthropic首席产品官Mike Krieger与Sarah Guo的对谈
- Peter Yang + 阿曼:2025年将定义你产品经理职业生涯的AI技能 | Aman Khan (Arize)
- DeepLearning.ai与吴恩达合作的评估课程
- 提示词优化指南:https://arize.com/course/prompt-optimization/
- Arize评估中心(免费!):https://arize.com/llm-evaluation
- Peter Yang + Scott White:独家揭秘:最佳编程与写作AI模型的内幕 | Scott White (Anthropic)
谢谢你,阿曼!
祝你本周充实而高效 🙏
如果你觉得这份newsletter有价值,请分享给朋友,如果还没有订阅的话,也请考虑订阅。我们提供团体折扣、礼品选项和推荐奖励。
诚挚致意,
Lenny 👋